洛谷题库 P8868 [NOIP2022] 比赛
本文记号可能稍显凌乱,但都能在题面或者前文中找到定义。
部分分
20 pts – n,Q≤3000
考虑枚举所有 O(n2) 个区间,预先计算它们本身的答案。记
ga(l,r)gb(l,r)={max{ai∣l≤i≤r},0(1≤l≤r≤n)otherwise={max{bi∣l≤i≤r},0(1≤l≤r≤n)otherwise
则做前缀和 s(l,r)=∑i=lrga(l,i)gb(l,i),对于询问 [ql,qr] 只需回答 ∑i=qlqrs(i,qr) 即可。
令 n,Q 同阶,时空复杂度 O(n2)。
32 pts – n≤2.5×105,Q≤5
思考单独计算每个询问的答案。
设 lbd(i) 满足 (lbd(i)=1∨albd(i)−1>ai)∧max{aj∣lbd(i)≤j<i}<ai,也即 ga(l,r)=max{aj∣l≤j≤r}=ai,应满足 lbd(i)≤l≤i;rbd(i) 同理。它们可以由前后两遍单调栈 O(n) 求出。
对于询问 [ql,qr],从 a 的角度出发考虑贡献。记 fb(p,i,j,q)=l=p∑ir=j∑qgb(l,r)(p≤i∧j≤q)若对于所有 i∈[ql,qr],我们能求出 fb(max(lbd(i),ql),i,i,min(rbd(i),qr)),那么将其乘上 ai 累加到答案中。
设想一个矩阵 B,有 Bl,r=gb(l,r),则现在我们有 qr−ql+1 个上述询问,要求出矩阵区域和。
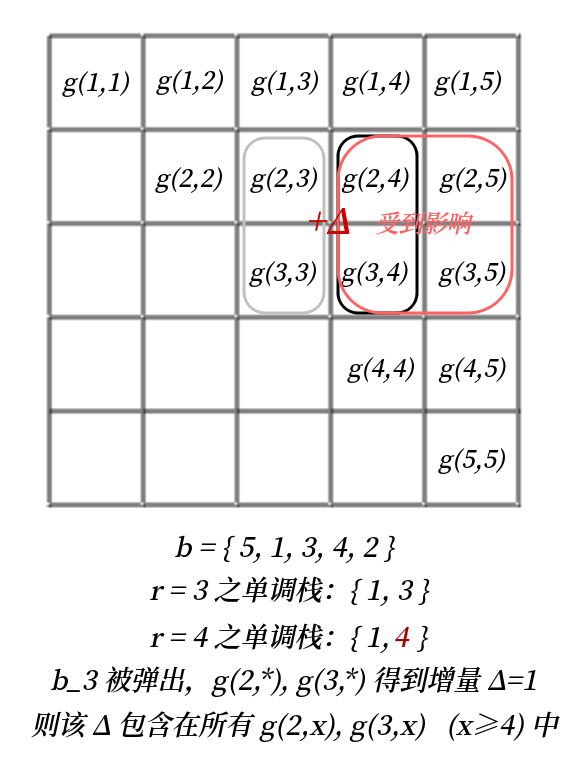 如果我们只计算一列中连续几行元素的和,它是一个经典扫描线问题:借助单调栈和区间加线段树,我们能轻松维护“在 r 分别为 1,2,⋯,n 时,任意 l (l≤r) 的 gb(l,r)”。更具体地,我们维护一个 b 的最大值单调栈,并从小到大枚举 r。记现在单调栈保存的下标为 t1,t2,⋯,tk,令 t0=0,满足 ∀i∈[1,k),bti>bti+1。我们试图将 r 压入栈中,考虑 gb(l,r−1) 怎样变化到 gb(l,r)。当我们弹出 ti 时,显然有 ∀l∈(ti−1,ti],gb(l,r−1)=bti,gb(l,r)=br⇒gb(l,r)−gb(l,r−1)=br−bti。于是在弹出过程中,在线段树上对区间 (ti−1,ti] 中每个元素加上 br−bti,即可维护 r 时的 gb(l,r);自然,如果 l 在弹出过程中未被波及,则 gb(l,r)=g(l,r−1)。(最后单点更新 gb(r,r)=br)
如果我们只计算一列中连续几行元素的和,它是一个经典扫描线问题:借助单调栈和区间加线段树,我们能轻松维护“在 r 分别为 1,2,⋯,n 时,任意 l (l≤r) 的 gb(l,r)”。更具体地,我们维护一个 b 的最大值单调栈,并从小到大枚举 r。记现在单调栈保存的下标为 t1,t2,⋯,tk,令 t0=0,满足 ∀i∈[1,k),bti>bti+1。我们试图将 r 压入栈中,考虑 gb(l,r−1) 怎样变化到 gb(l,r)。当我们弹出 ti 时,显然有 ∀l∈(ti−1,ti],gb(l,r−1)=bti,gb(l,r)=br⇒gb(l,r)−gb(l,r−1)=br−bti。于是在弹出过程中,在线段树上对区间 (ti−1,ti] 中每个元素加上 br−bti,即可维护 r 时的 gb(l,r);自然,如果 l 在弹出过程中未被波及,则 gb(l,r)=g(l,r−1)。(最后单点更新 gb(r,r)=br)
但我们要计算的是若干连续列的和。先利用前缀和简化:有 fb(p,i,j,q)=fb(p,i,1,q)−fb(p,i,1,j−1)。fb(p,i,1,q) 即上述过程中线段树上区间 [p,i] 内元素前 q 轮的历史版本和。不妨考虑上述过程中每一次的增量在最终答案中的贡献。容易发现,如果在 r 处执行了某次区间加操作,增量为 Δ,且下标 l 在该区间内,那么它对所有 gb(l,r’) (r’≥r) 都有 Δ 的线性贡献,于是对 fb(p,i,1,q) (q≥r,l∈[p,i]) 的贡献为 (q−r+1)Δ=qΔ−(r−1)Δ。易得位置 l 在前 r 轮累加的所有 Δ 就是 ga(l,r);而 r,Δ 只与区间加操作相关,q 只与查询相关,故而我们开设另一棵线段树,维护所有 −(r−1)Δ 的区间和即可计算上述式子。
时间复杂度 O(Qnlogn)。可以将上文中对每个询问构造的 fb 查询全部记录后,只执行一遍扫描线求出答案,最后统一回答,常数更小。
赛时代码(52 pts)
32 pts – a 是等概率随机生成的排列
CWOI 好像只有 hfy 赛场上写了该部分分。不过他的线段树被卡常了,怪出题人只给了 2s。
引理
在 n! 个全排列中等概率随机选择一个排列 p,p 所构建的笛卡尔树的树高期望是 O(logn) 的。
我们试图找到一个复杂度只跟 a 强相关的算法,以充分利用这一性质。
不难发现,假如有 lbd(i)≥ql∧rbd(i)≤qr,那么我们总是可以直接累加 aifb(lbd(i),i,i,rbd(i)) 到答案中,不用考虑询问给定的限制。则我们可以用上文所述方法在 O(nlogn) 时间内求出 aifb(lbd(i),i,i,rbd(i)) (i=1,2,⋯,n)。
考虑在 a 随机的情况下,有多少位置 i 不能采用上式结果,而须考虑 ql,qr 的影响。显然,若 amx=ga(ql,qr),则位置 mx 的答案可能要重新计算——必有 lbd(mx)≤ql∧rbd(mx)≥qr(否则和它是区间最值的条件相悖)。
考虑不断从区间最值位置向两侧迭代,也即
⎩⎨⎧lmxk=mx,almxk=ga(ql,lmxk−1−1),lmxk is undefined(k=0)(lmxk−1>ql)otherwise⎩⎨⎧rmxk=mx,armxk=ga(rmxk−1+1,qr),rmxk is undefined(k=0)(rmxk−1<qr)otherwise
则不难说明有且仅有 lmxk,rmxk (k=0,1,⋯) 这些位置需要重新计算答案——其他所有位置 i 的 lbd(i),rbd(i) 最多延伸到(向左)lmxk+1 或者(向右) rmxk−1,可以直接采纳预处理答案。
由于均有 lmxk 是 lmxk−1 在笛卡尔树上的子树元素(rmx 同理),且树高为 O(logn) 的,故而暴力重算的复杂度得到保障。我们用 ST 表 找到 lmxk 和 rmxk,将 O(Qlogn) 个询问挂载到对应右端点,最后统一做一遍上文所述的扫描线,复杂度为 O(Qlog2n+nlogn)。
需要使用区间加区间求和树状数组优化常数才能通过,或者尝试用 O(n) 修改 O(1) 查询的块状数据结构平衡复杂度。(实际上本解法可以直接通过上一部分分。)
代码(84 pts)
正解(线段树)
当然了,我们有更简洁易写的分块做法。您可以移步别的题解。
我觉得出题人完全可以再给一组部分分:∑qr−ql+1≤?×105。
设想矩阵 F,满足 Fi,j=ga(i,j)gb(i,j)。记
f(p,i,j,q)=l=p∑ir=j∑qFl,r=l=p∑ir=j∑qga(l,r)gb(l,r)
则题目所给询问,等价于问左上角为 (ql,ql),右下角为 (qr,qr) 的子矩阵元素之和。又因为可以认为有 ∀l,r,n≥l>r≥1,Fl,r=0,则我们把左上角变成 (ql,1),不影响结果。于是就变成了求 f(ql,qr,1,qr)。
我们尝试对于 r=1,2,⋯,n,直接维护每个 l 的 ga(l,r)gb(l,r),同时维护 a,b 两序列的最大值单调栈。由于二者可能在第 r 轮内先后更新,故为行文方便,下文中将用 ga(l) 直接代指目前线段树上维护的 ga(l,r),ga(l)’ 则是相对于目前发生了改变的值;gb(l) 同理。
则在更新 a 的单调栈时,在某个位置 l 产生的增量 Δa=ga(l)’−ga(l) 将会导致 l 的答案从 ga(l)gb(l) 变成 (ga(l)+Δa)gb(l);更新 b 的单调栈时同理。则若我们在线段树上每个节点维护子区间的 ga(l) 之和,gb(l) 之和以及 ga(l)gb(l) 之和,现在每个位置产生增量 Δa,Δb,有 l∑ga(l)’gb(l)’=l∑(ga(l)+Δa)(gb(l)+Δb)=(l∑ga(l)gb(l))+(l∑ga(l))Δb+(l∑gb(l))Δa+l∑ΔaΔb
Δa,Δb 均导致线性贡献,显然满足结合律。于是用带 Δa,Δb 延迟标记的线段树维护,就能在 O(logn) 的时间内,在右端点扫描到 r 时,查询 ga(l,r)gb(l,r) 的区间和。
现在回顾部分分 O(nlogn) 处理单个查询的解法。我们分离了每一次的增量造成的贡献,并在最终线性累加回去。实际上对于上述更复杂的贡献,也能如法炮制:同样有 f(p,i,1,q) 是线段树上的区间历史版本和。仍考虑 ga(l)gb(l) 怎样变化到 ga(l)’gb(l)’。扫描到 r 处更新 a 的单调栈时,若在位置 l 产生增量 Δa,则对于 q≥r 的所有版本,ga(l,q)gb(l,q) 都包含增量 Δagb(l)。那么,对于某个查询 f(p,i,1,q) (l∈[p,i],q≥r),该次更新的增量造成的总贡献为 Δagb(l)(q−r+1),拆分成 Δagb(l)q−Δa(r−1)gb(l)。b 的更新同理:Δbga(l)q−Δb(r−1)ga(l)。
不难验证,对于一个确定的 l,在所有 r (r≤q) 处的两个蓝字部分贡献之和仍恰等于 ga(l,q)gb(l,q),直接依照上文在线段树上维护区间和即可。现在着重考虑红字的求和。
我们尝试对于每个位置 l 维护 h(l),表示扫描线扫到 r 时位置 l 的红字贡献之和。
引理 1
对于一棵未采用标记永久化的线段树,某个叶子结点到根的路径上,未下放延迟标记的节点是以叶子为首的一个非空前缀。
引理 2
记上文中“只维护第 r 轮的 ga(l,r)gb(l,r) 区间和”线段树上,节点 x 的延迟标记为 Δa,x,Δb,x。设线段树上管辖 ga(l)gb(l) 的叶子结点为 x1,它和若干祖先构成的链为 x1,x2,⋯,xk,xk 为某次操作递归访问的终止节点(此即引理 1 中的前缀)。则任一时刻,ga(l) 的真实值等于 ∑i=1kΔa,xi,而 xi 采用的“ga(l)”实际上是 ∑j=1iΔa,xj;gb(l) 之于 Δb,x 亦然。
 这两条引理都是很容易验证的。
这两条引理都是很容易验证的。
考虑怎样维护 h(l) 的区间和。假若扫描线扫描到第 r 轮,我们更新了 b 的单调栈,使得一段区间的 h(l)’=h(l)+Δb(r−1)ga(l)。则将当前 ga(l) 的值记作 ca,它的贡献仍然是线性的:访问线段树某一节点时,由于其所有祖先的延迟标记都已下放,我们获得的正是 ga(l) 的真实值。故可以立刻更新节点 xk 的
l∑h(l)’=(l∑h(l))+Δb(r−1)l∑ga(l)
此后该区间可能经过了若干次更新,维护的 ga(l) 和 Δa,x 可能发生变化,但那一次修改所采用的的 ca 是不变的(参见上图)。为了保证下放后 h(l) 增量的一致性,我们将 ca 拆分成 Δa,xk+∑i=1k−1Δa,xi,h(l) 的增量变成
caΔb(r−1)=Δa,xkΔb(r−1)+i=1∑k−1Δa,xiΔb(r−1)
如上图所示,蓝字就是 xk−1 所维护的“ga(l)”,它在把标记 Δa,xk 下放到 xk−1 前保持不变,我们将其加以利用。故而下放时,依次作如下更新:令延迟标记 Δβ,x 为应用到 x 上且还未下放的 Δb(r−1) 之和(Δα,x 是 Δa(r−1) 之和);有 xk−1 维护的
l∑h(l)’=(l∑h(l))+Δβ,xk(l∑ga(l))+Δα,xk(l∑gb(l))
(∑lga(l),∑lgb(l) 暂未更新);对于红字,我们在对 xk 作修改时即立刻保存 Δb(r−1)Δa,xk,将其累加到另一延迟标记中,记作 Δco,xk;下放时即有
l∑h(l)’=(l∑h(l))+(l∑Δco,xk)
(注意到红字累加的是常系数,与来自于对 a 还是对 b 的修改无关,故而 a 的修改共用 Δco,xk)
Δβ,xk,Δα,xk 的下放更新是简单的,将它直接累加到 Δβ,xk−1,Δα,xk−1 上即可;而 Δco,xk 下放时,由上图可得有
Δco,xk−1’=Δa,xk−1Δβ,xk+Δb,xk−1Δα,xk+Δco,xk
这些更新完成后,再行处理 ∑lga(l),∑lgb(l) 和 ∑lga(l)gb(l) 的更新。于是我们对每个节点 x 维护九元组 (∑lga(l),∑lgb(l),∑lga(l)gb(l),∑lh(l),Δa,x,Δb,x,Δα,x,Δβ,x,Δco,x)。题目所给每个询问 [ql,qr],都只需在扫到第 qr 轮时区间查询 ∑l=qlqrqrga(l)gb(l)−h(l)。
时间复杂度 O(Qlogn+nlogn),常数大。
R96818778 记录详情
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
#include <bits/stdc++.h>
using namespace std;
#define inl inline
#define newl putchar('\n')
typedef long long ll;
typedef unsigned long long ull;
typedef pair <int, int> pint;
#define fst first
#define scd second
#define all(p) begin (p), end (p)
#define empb emplace_back
constexpr int N = 250010;
int _test, n, m, l, r, a[N], b[N]; ull ans[N];
int sta[N], topa, stb[N], topb;
vector <pint> q[N];
struct seg_tree {
struct info { ull da, db, dalp, dbta, dco; };
struct node { ull l, r, gasum, gbsum, gagbsum, hsum; info tag; } t[N<<2];
info inc; ull idx, L, R;
void build (int x, int l, int r) {
t[x].l = l, t[x].r = r;
if (l == r) return;
int mid = l + r >> 1;
build (x<<1, l, mid),
build (x<<1|1, mid + 1, r);
}
inl void saku (node &nde, const info &tag) {
static ull len; len = nde.r - nde.l + 1;
info &_tag = nde.tag;
const auto &[da, db, dalp, dbta, dco] = tag;
nde.hsum += dalp * nde.gbsum + dbta * nde.gasum + dco * len;
nde.gasum += da * len, nde.gbsum += db * len;
nde.gagbsum += da * db * len + db * nde.gasum + da * nde.gbsum;
_tag.dco += dco + _tag.db * dalp + _tag.da * dbta;
_tag.da += da, _tag.db += db,
_tag.dalp += dalp, _tag.dbta += dbta;
}
inl void down (int x) {
saku (t[x<<1], t[x].tag),
saku (t[x<<1|1], t[x].tag),
memset (&t[x].tag, 0, 40);
}
inl void post (int x) {
node &nde = t[x], &ls = t[x<<1], &rs = t[x<<1|1];
nde.gasum = ls.gasum + rs.gasum,
nde.gbsum = ls.gbsum + rs.gbsum,
nde.gagbsum = ls.gagbsum + rs.gagbsum,
nde.hsum = ls.hsum + rs.hsum;
}
void add (int x) {
if (t[x].l >= L && t[x].r <= R)
return saku (t[x], inc);
ull mid = t[x].l + t[x].r >> 1; down (x);
if (L <= mid) add (x<<1);
if (R > mid) add (x<<1|1);
post (x);
}
inl void add (int l, int r, ull da, ull db, ull idx) {
inc = { da, db, (1ull-idx)*da, (1ull-idx)*db,
(da&&db) * (1ull-idx)*da*db } ;
L = l, R = r, add (1);
}
ull query (int x) {
if (t[x].l >= L && t[x].r <= R)
return t[x].gagbsum * idx + t[x].hsum;
ull mid = t[x].l + t[x].r >> 1;
down (x); ull res = 0;
if (L <= mid) res += query (x<<1);
if (R > mid) res += query (x<<1|1);
return res;
}
inl ull query (int l, int r, int _idx) {
return L = l, R = r, idx = _idx, query (1);
}
} seg;
int main () {
read (_test, n);
for (int i = 1; i <= n; ++i) read (a[i]);
for (int i = 1; i <= n; ++i) read (b[i]);
seg.build (1, 1, n);
read (m);
for (int i = 1; i <= m; ++i)
read (l, r), q[r].empb (l, i);
for (int r = 1; r <= n; ++r) {
static int dt;
while (topa && (dt = a[r] - a[sta[topa]]) > 0)
seg.add (sta[topa-1]+1, sta[topa], dt, 0, r), --topa;
while (topb && (dt = b[r] - b[stb[topb]]) > 0)
seg.add (stb[topb-1]+1, stb[topb], 0, dt, r), --topb;
seg.add (r, r, a[r], b[r], r);
sta[++topa] = stb[++topb] = r;
for (const auto [l, id] : q[r])
ans[id] = seg.query (l, r, r);
}
for (int i = 1; i <= m; ++i)
print (ans[i]), newl;
return 0;
}



